
Deferring errors in Stacksmith
Why Compilers need to Recover from Errors
When parsing a programming language (like Stacksmith’s HyperTalk-derivate “Hammer”), the easiest way to handle errors is to just stop processing a source file at the first error.
However, if you do it like many modern languages do and use the compiler itself to perform the code analysis needed for editor integration, like syntax coloring, auto-completion etc., you can’t do that.
Users don’t type valid code from top to bottom. You will constantly run into situations where the user has typed partial code into the middle of the document, and you still need to present the user with code navigation information for the code below it.
Simple Recovery Approaches
Depending on the design of your language’s syntax, recovering from such an error and making a reasonable attempt at picking up after incomplete/erroneous code might be harder or easier.
But usually, it involves simply pretending the current construct that was erroneous was complete, and scanning down until you find a spot that looks like the start of the next construct at that level. Of course, this gets harder the more ambiguous your syntax is, and also is difficult if your language supports recursive nesting of constructs.
Luckily, in Stacksmith’s Hammer language it is fairly easy to recover, so let’s use that as a simple example, and illustrate what I do.
Error Recovery in the Hammer Parser
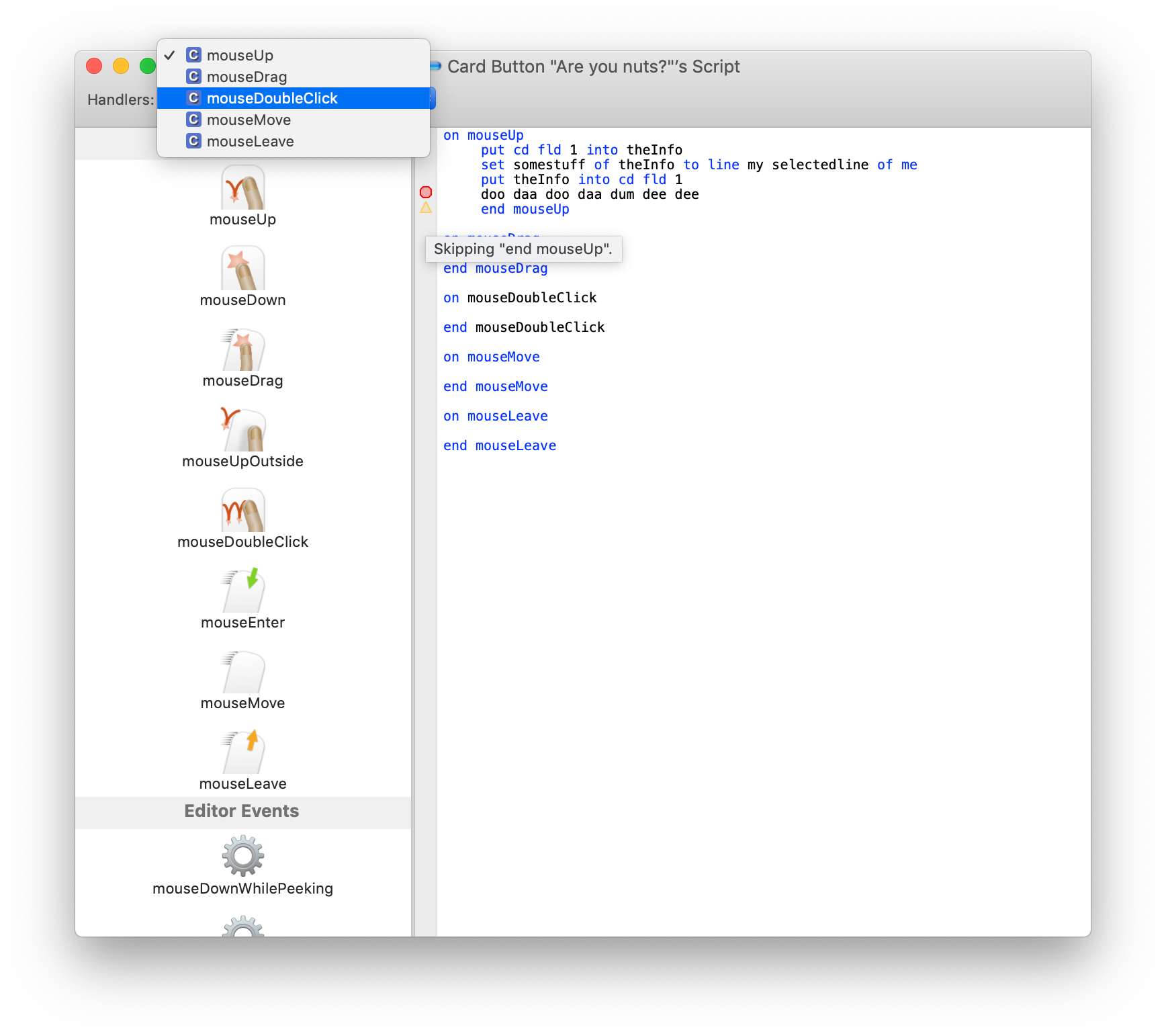
A typical Hammer script looks like this:
on startUp
if registration() is "expired" then
answer "Your license has expired." with "Quit"
doMenu "Quit Stacksmith"
end if
end startUp
on quit
repeat with x = 1 to the number of stacks
if the changeCount of stack x > 0 then
answer "Save changes to stack “” & the short name of stack x & "”?" with "No" or "Yes"
if it is "Yes" then
save stack x
end if
end if
end repeat
pass quit -- let Stacksmith do the default behaviour for quitting
end quit
Now imagine that, somehow, doMenu was actually not a valid command and the parser didn’t know what to do here. What would it do?
Given our main interest in continuing parsing is that we can still fill our code navigation popup menu with all the function names from this script, the easiest approach would be to pretend the startUp function was complete here and just scan down until the start of the next function, indicated by an on token.
So languages with a clear start token for functions like on or func have a clear advantage here. Stacksmith not only has that, but also has clear end statements (because the end is always followed by the name of what it ends). So theoretically we could even scan only for the end token, and continue there. We could even just scan for the next end if and make our first recovery attempt within the current function.
In Stacksmith that didn’t make sense, so I literally just ignore everything until I hit a line starting with on, but for languages like C, where you declare global variables in between your top-level functions, it might make sense to scan for end indicators first.
Recording Errors
Okay, so we’ve skipped the rest of the startUp function somehow and continue parsing at the on quit function, but what do we do with the error? Before, we were able to just throw an exception containing the error information, but now we’d at least have to catch that exception at a higher level in our parser (i.e. at the loop that calls parseFunction() repeatedly until we have parsed the entire script).
Well, wherever we swallow the error and do our recovery, we have to remember the error. Have an array somewhere and add the error information (line number, error message, offset etc.) to it. Then once the parser has run through, we look at the error information. If there is none, we’ve successfully parsed, if there are entries in the list, we’ve failed somewhere.
If we’re just collecting a list of function names for navigation, we can ignore this information. Otherwise, we could present the error list to the user, either by printing little icons in the code editor indicating the error lines, logging the errors to the console, or presenting them in the issue list window. Whatever makes sense for the situation you’re using the parser in.
Presenting Errors at Runtime
HyperTalk (and by extension, Hammer) is a language that is supposed to feel “human”. HyperCard’s designers knew that a human might draft a partial or buggy function and not use it, but leave it in the script. As such, it tries to be tolerant even when running a script. If, in the above case, it failed to parse startUp, it still lets you call quit. Which is good, because a Stacksmith stack is “live” while you develop it. If it presented an error message every time someone tried to call a method in the script you would make one typo and the app would basically become unusable.
But what happens if the parser failed to parse startUp, and then you call startUp?
What Stacksmith actually does when it encounters a parse error is that it writes some code into the startUp function that aborts the script and presents the error message. So if you ever call a broken function, it will execute the first few commands, and then present the error. This command could even attach the debugger at this point and let you see what the current values are up to this point, just like it can with every runtime error.
Combined with showing error icons next to each problematic line, this is a good compromise between letting users have incomplete or erroneous scripts, and leaving the program useful. If the user pays a little attention, she’ll see the error icon on her line and investigate. If she needs to save and shut down the machine, she can do that and diagnose the error later. Whatever works best for our users.
Is this Something Every Language Does?
No. Most compiled languages will likely err on the side of performing compile-time checks. Other languages have a dedicated, simpler parser for their function navigation (like, a regular expression that just finds all lines starting with “on” or whatever) that might yield some false positives or fail to recognize functions defined using macros, but on the other hand don’t look at enough of the code to stumble when the user has incomplete code.
But for Stacksmith, this makes sense.
For other compilers, recovery approaches can help you diagnose errors better. For example, when the Clang C compiler encounters the name of a data type it does not know, it doesn’t stop parsing. If it knows that there can only be the name of a type in this location, it just adds a fake “error type” entry for this type name and tries to muddle on.
And then it might later encounter a definition for a type of this name, see that there already is an “error type” for that, and it can change the error message from “unknown type Foo” to “type Foo declared too late, declared on line 50, used on line 5.” and could even offer to move the declaration of the type up.
Moreover, if the type is only used as a pointer, but its fields or size aren’t accessed, it could even automatically insert a forward-declaration for this type instead of moving the entire type.
So while it may initially seem wasteful to keep parsing once you know an error is in the code, there are occasions where you can make your compiler better.